
바야흐로 大AI시대다. 하루가 다르게 기술이 발전하고 있고, 이를 적용할 수 있는 범위도 넓어지고 있는 중이다.
하지만 여전히 우리는 영상이나 게임 콘텐츠 안에서 콕 집어 말하기 어려운 어색함이나 아쉬움을 느끼곤 한다. 특히 사람 또는 캐릭터 '표정'의 표현은 더더욱 그렇다.
NDC(넥슨 개발자 컨퍼런스) 현장에서 NC AI 장한용 실장이 특히 강조해 소개한 것도, 표정 애니메이션 생성 기술이었다.
'바르코(VARCO) 싱크 페이스'로 만든 얼굴 표현은 기존 기술들과 비교해 어떤 점이 달랐을까. 그리고 장한용 실장은 현재의 업계 기술 현황과 앞으로 나아가보면 좋을 지점에 대해 어떤 시선을 보여줬을까./디스이즈게임 김승준 기자
 ▲ NC AI 장한용 실장
▲ NC AI 장한용 실장
# 왜 얼굴 표정을 구현하는 애니메이션이 중요한가


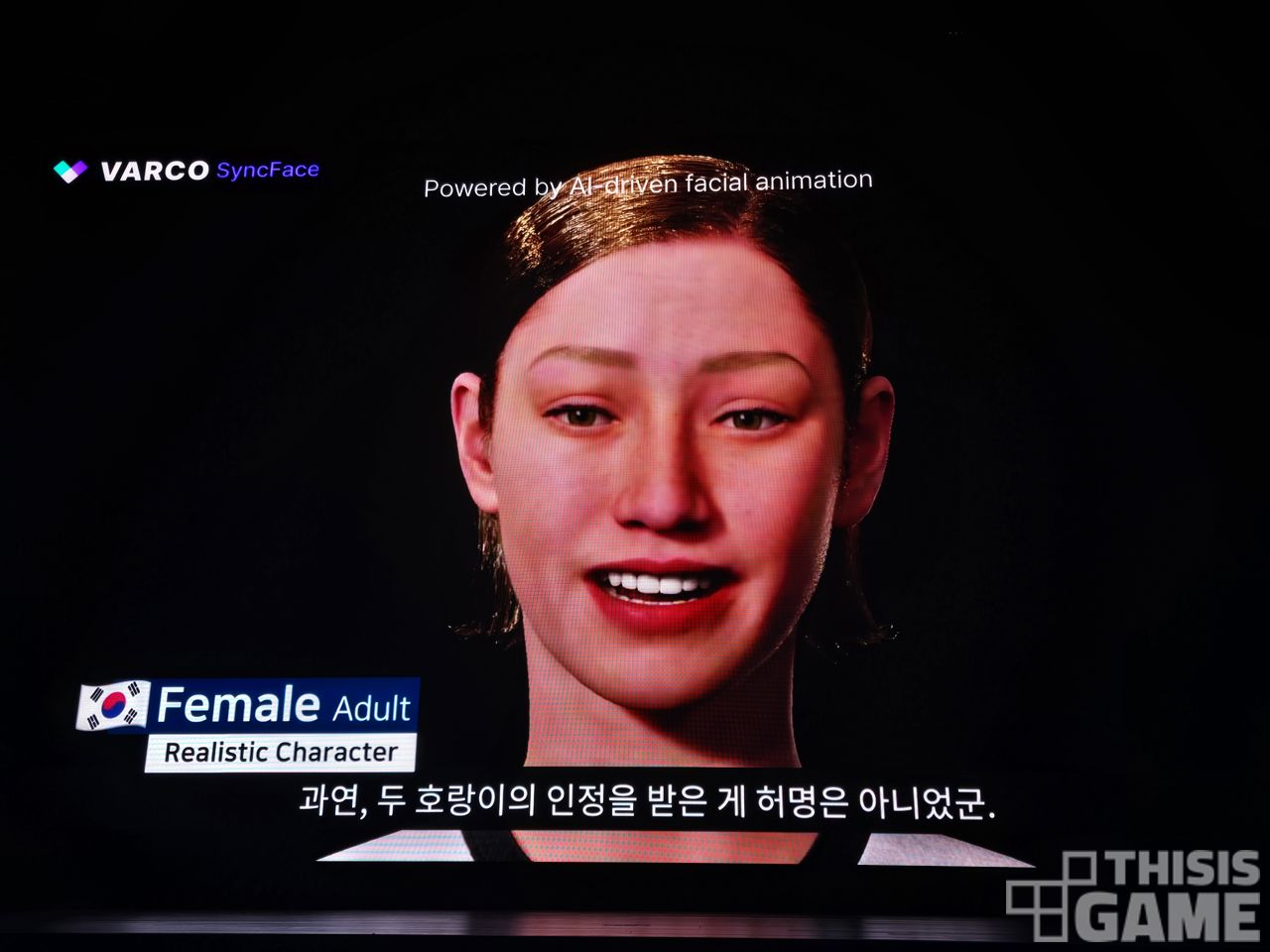
위의 사진들은 현장에서 소개된, 음성 발화에 맞게 바르코 싱크 페이스를 적용한 모습들이다.
장한용 실장은, 게임 업계의 비주얼 퀄리티는 워낙 상향 평준화되어 있고, 바디 모션 캡처와 관련된 영역도 상당히 좋아졌지만, 얼굴 애니메이션에 대해선 아직 개선이 더 필요하다는 게 업계인들의 의견이라 전했다.
이용자들 또한 입 모양을 입힌 것과 아닌 애니메이션에 대해 큰 차이를 체감하기도 한다.
여러 개발사들 또한 페이셜 표현에 대한 중요성을 잘 알고 있다. 예를 들어, 캡콤의 <몬스터 헌터> 시리즈는 얼굴 표현에 대해서만 외주 업체 5곳에 맡길 정도다.
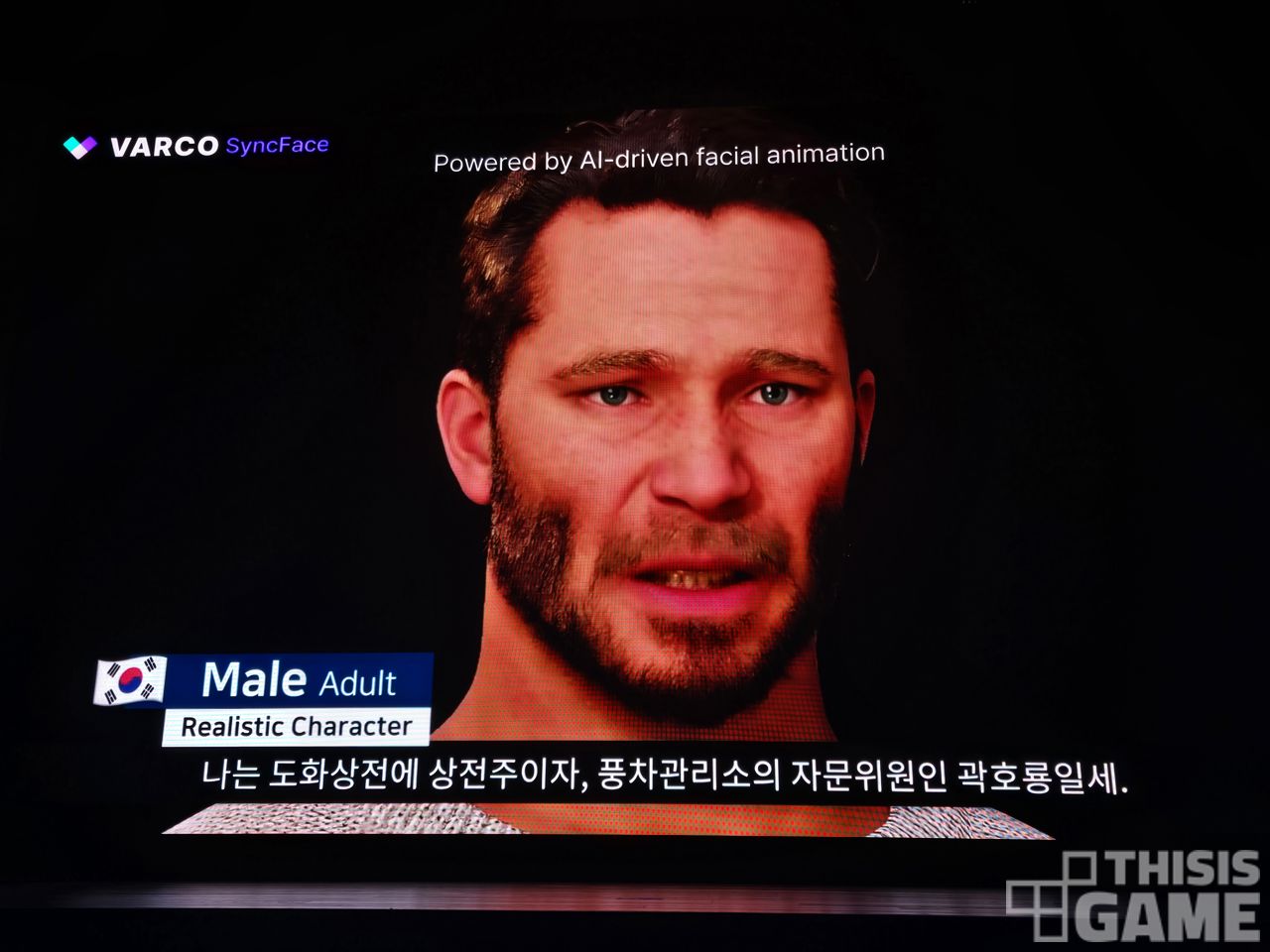

AAA 게임 제작 환경에서는 모션 캡처를 할 때 얼굴 페이셜 캡처도 같이 하는 편이지만, 제작 비용과 들어가는 시간, 주연 및 조연 배우의 역량의 차이에 따라 편차가 큰 편이다.
또한 바디 모션 캡처에 비해 품질이 좋은 편이 아니라서, 일반적으로 아티스트들이 후작업을 손으로 다 하는 편이라고 한다.
그래서 AI를 이용해 자동으로 립싱크를 해주거나, 표정을 생성하는 기술을 여러 기업들이 꽤 오래 시도해왔다.
# 여러 기업들의 다양한 솔루션이 나왔으나...
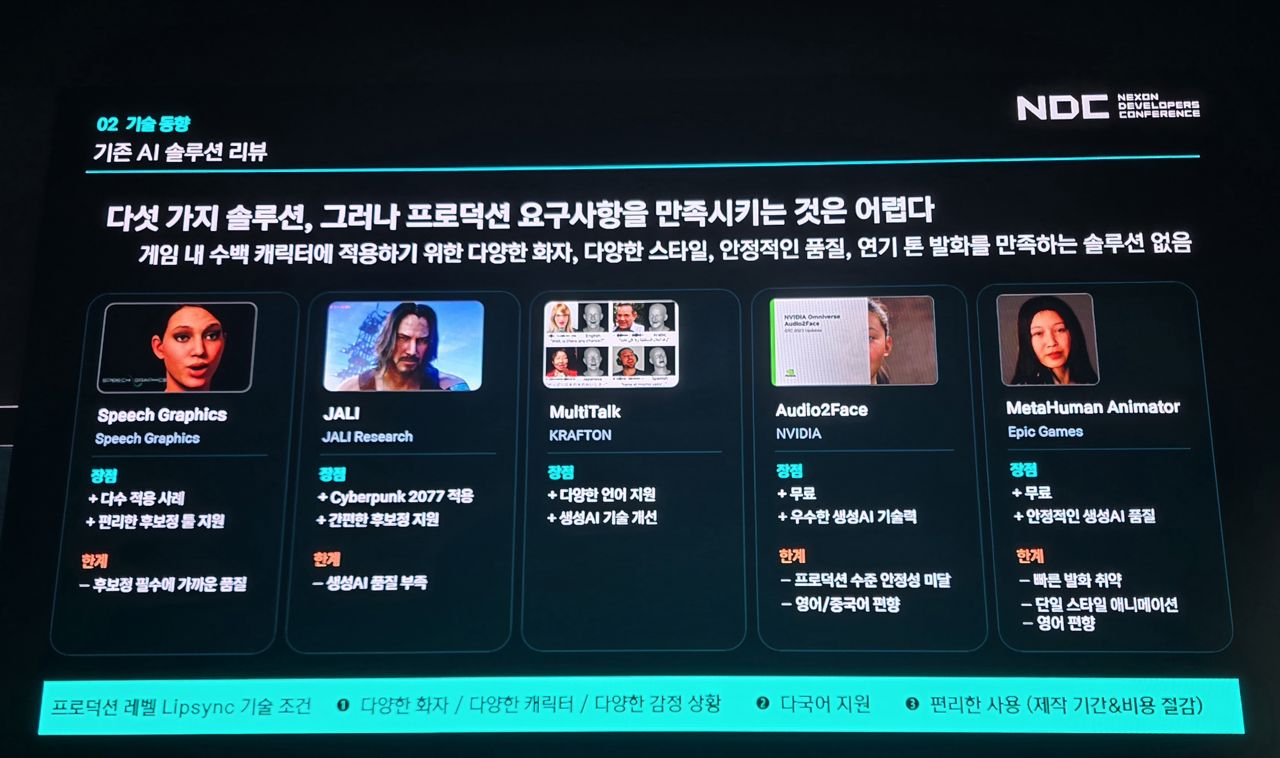
엔비디아, 에픽게임즈 등을 비롯해 여러 기업들이 표정 생성, 버추얼 휴먼 등의 기술을 선보여 왔다. 관련 논문도, 이 분야에서 대표적인 2017년 엔비디아의 논문 이후로 많이 나온 편이다.
특히 엔비디아와 에픽게임즈의 모델은 무료라는 지점에서 더 주목할 만하다. 하지만, 각각의 모델은 생성한 결과물의 품질에 있어 각기 다른 아쉬운 지점들이 꽤 있다고 한다. 상용화하기 위해선 개선이 많이 필요하다는 의미다.


가령, 엔비디아의 기술에선, 게임 콘텐츠처럼 과격한 연기 톤으로 발화할 때 취약했고, 음성 효과가 들어갈 때 입술이 떨리는 오류가 생길 때도 종종 있었다고 한다.
에픽게임즈 쪽은 입술 표현이 너무 과하게 부드럽게 나와서 오히려 비현실적으로 느껴지기도 했고, 감정 표현에서 개선이 필요한 지점들도 있었다고 한다.
장한용 실장은 기반이 되는 기술적 배경은 이미 많이 확보됐다고 보는 쪽이었다. 하지만 전체적인 품질의 안정성이 필요했고, 하자가 없는 결과물이 나오게 하는 것이 목표였다. 동시에 실무적 업무 부하는 최소화하는 것도 중요했다.
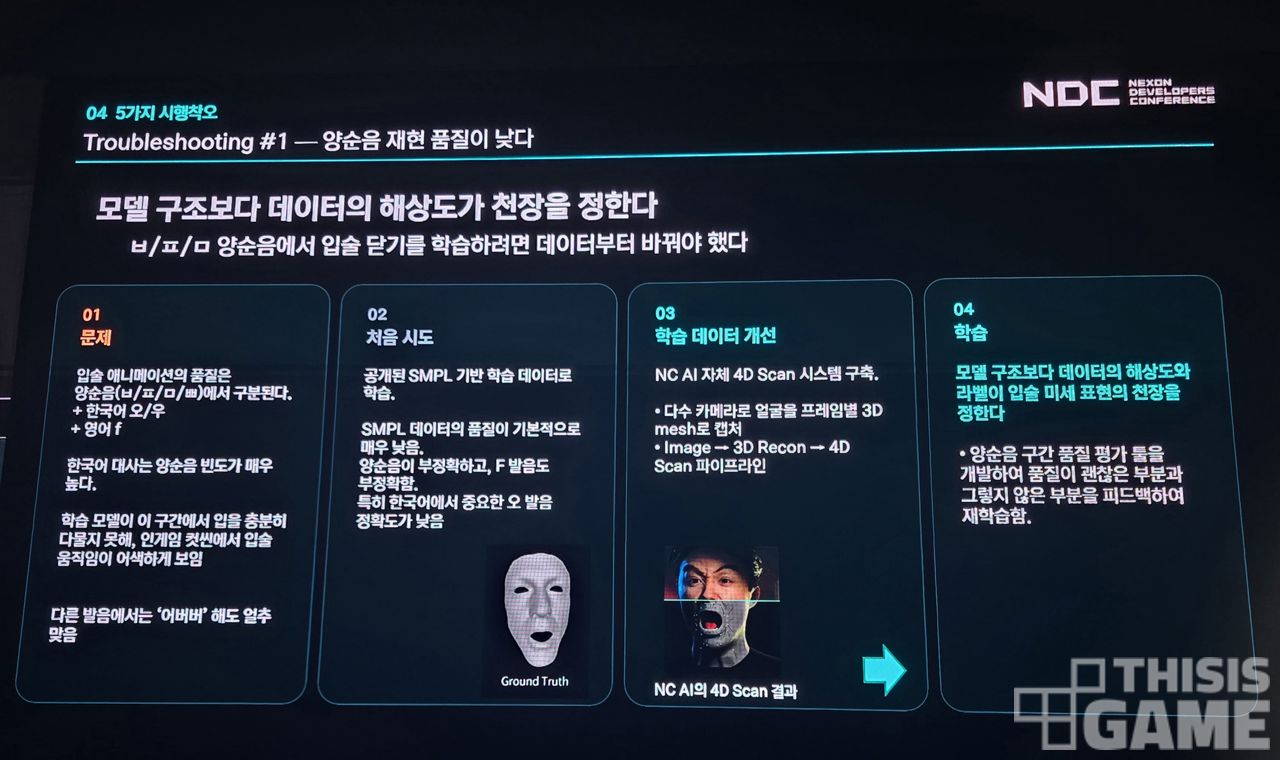
이를 위해 학습 데이터를 개선할 필요가 있었다.
특히 한국어 발음에서는 양순음(비읍, 피읖, 미음, 쌍비읍)에서 입술이 닫혔다 열려야 하는데, 기존 모델에서는 이런 움직임이 어색하거나 제대로 표현되지 않는 때가 많았다. 또한 한국어 발음에서 중요한 'ㅗ'(오) 발음도 정확도가 낮았다.
모델 구조보다는, 데이터르 어떻게 라벨링 하느냐에서 결과가 달라질 수 있다는 것을 확인하며 시행착오를 거쳐갔다고 한다.


그렇게 소개된 적용 사례 중 일부다. NC AI는 기존의 데이터셋 원본 자료들이 양순음을 제대로 표현하지 못하고 있다고 봤고, 이를 위해 장비로 양순음 데이터가 더 많이 들어가게 직접 캡처를 해서 데이터셋도 새로 확보했다.
그렇게 생성된 페이셜은 바로 리깅(뼈대) 수정을 할 수 있게 후보정이 쉬운 상태로 나온다.

다만, 이는 한 사람, 한 캐릭터에 대해서는 적용이 쉽지만, 게임 안에는 여러 캐릭터가 다양한 표정을 지으며 등장한다는 문제점으로 이어졌다.
남자, 여자, 어린아이, 노인 등 입력값을 많이 넣는 시도 외에도, 매핑 연결도 매우 중요했다고 한다.
가령 음성을 입력해주는 측면에서는, 여러 화자의 결과를 1명의 데이터에 치환하며 매핑해도 괜찮았다고 한다. 바꿔 말하면 하나의 캐릭터에 여러 음성 입력값으로 시험해볼 수 있었다는 것이다.
그러나 표정 출력의 과정에서는 여러 캐릭터의 데이터가 명확히 구분되어야만 했다. 예를 들어 윗입술은 남성의 표정, 아랫입술은 다른 여자 배우의 입술 모양, 눈은 또 다른 표정이 섞이면 쓸 수 없는 결과물이 나온 식이다. 섞이지 않게 하는 것이 핵심이었다.

학습 입력값이 많다고 꼭 좋은 것도 아니었다.
선이 명확한, 해당 감정을 표현하는 데 있어 특징이 강한 표정들을 중심으로 라벨링을 하고 연결지어주니 노이즈가 줄어들었다.
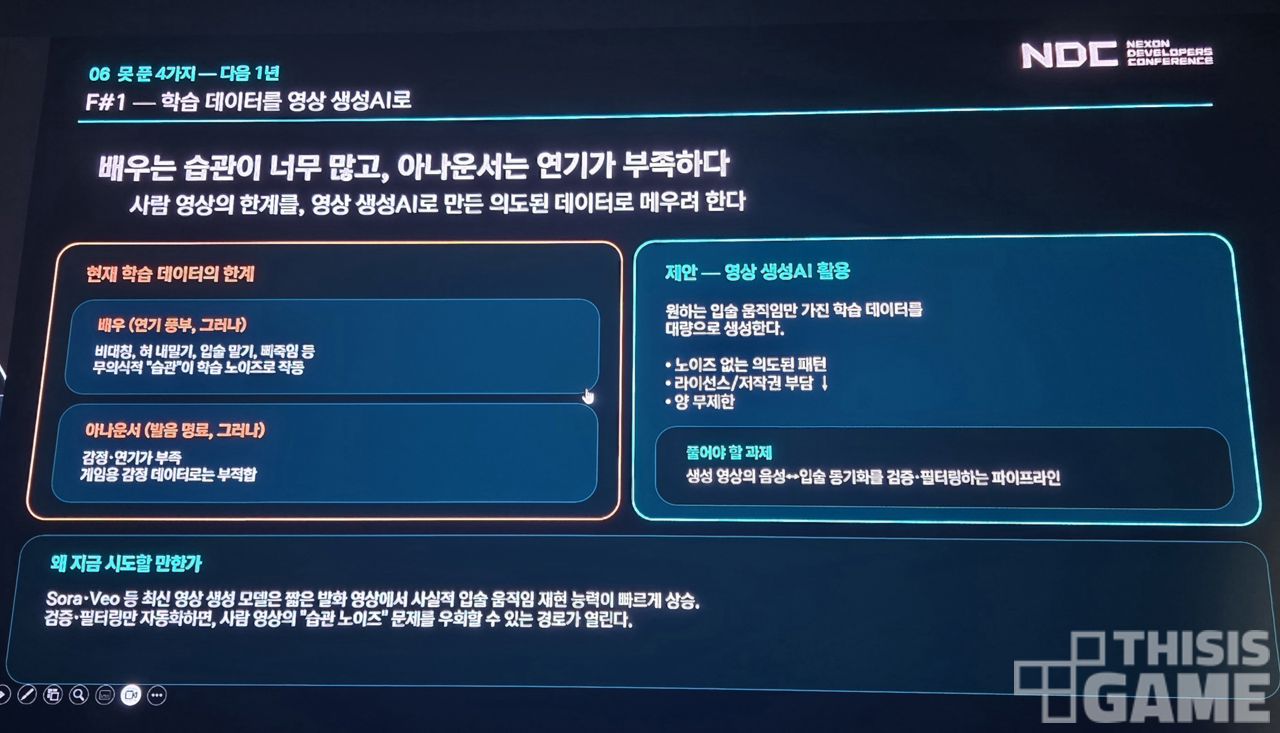
그러나 한계도 여전히 있었다. 현재 국내 해외의 표정 학습 데이터셋은 배우나 아나운서의 페이셜 캡처를 기반으로 하고 있다.
그런데 배우는 입술을 말거나 삐죽이기도 하고, 얼굴이 비대칭이거나, 혀를 내밀기도 하는 등 각자의 습관이 있어, 이게 학습 과정에서 노이즈로 작용하게 된다.
아나운서는 발음 표현에는 도움이 될 수 있으나, 감정과 표정의 표현에서 약점이 있다.
그래서 장한용 실장이 상상해본 미래는, 빠르게 발전하는 영상 생성 기술의 퀄리티를 봤을 때, 생성된 영상물을 학습물로 입력하는 것도 하나의 방법이 될 것이라는 예측이었다.

실무적으로는 게임에 적용될 때는 입술을 포함한 하관의 표현은 적용하지만 눈 표현 등에 제약을 거는 경우도 있었고, 실제 사람의 표정에 비해 인게임 모델링 구조상 표현의 한계가 있기도 했다.
앞서 도입부에서 모션 캡처 기술이 발달하고 나니 표정 표현에 대해 더 요구하게 됐다던 현황처럼, 입모양에 대한 표현이 더 정교해지니 눈의 표현, 제스처의 표현 등에 대한 요구도 뒤따라 더 늘어나기도 했다는 말도 전해졌다.
장한용 실장은 시간이 더 지나면, 이러한 기술들이 모두 통합되어 LLM(텍스트), TTS(음성 발화), 표정, 제스처까지 모두 적절하게 생성되는 날이 올 수 있으리라 예상했다.
 ▲ NC AI 장한용 실장
▲ NC AI 장한용 실장
