
유튜브, 틱톡, 인스타 같은 영상 매체 또는 도네이션이 포함된 라이브 방송을 많이 보시는 분들께 TTS(텍스트 투 스피치)는 이제 낯선 기술이 아닐 것입니다. 특징적인 말투나 자글자글한 음질도 연상되실 거예요.
동시에 많은 사람들이 상상해보기도 합니다. 이런 기술을 통해 오타쿠들의 심장을 울리게 할 만한 수준의 미소녀 음성 또한 만들어낼 수 있을까?
<블루 아카이브>를 서비스 중인 넥슨게임즈 IO 본부에서도 비슷한 연구를 진행 중입니다. IO 본부 내 머신러닝 팀 김명지 파트장은 이번 NDC(넥슨 개발자 컨퍼런스) 현장에서 한국어로 미소녀 목소리를 만들어온 과정을 소개했는데요.
하루가 다르게 AI 기술이 발전하고 있다곤 하지만 텍스트를 틀리지 않게 읽어주는 것과 자연스러운 발화를 하는 미소녀의 음성을 만드는 것에는 큰 차이가 있습니다. 그래서 IO 본부 안에서도 여러 시행착오를 거쳐왔는데요.
이번 기사에서는, 이러한 기술이 어디까지 와있는지 그리고 앞으로 어떤 부분들이 더 개선될 필요가 있는지, 강연 내용을 중심으로 소개해드리려 합니다./디스이즈게임 김승준 기자
 ▲ 넥슨게임즈 IO 본부 위그드라실 ML팀 김명지 파트장. 강연 콘셉트에 맞게 복장도 미소녀 스타일로 입고 연단에 올라오신 게 눈에 띄네요.
▲ 넥슨게임즈 IO 본부 위그드라실 ML팀 김명지 파트장. 강연 콘셉트에 맞게 복장도 미소녀 스타일로 입고 연단에 올라오신 게 눈에 띄네요.
# 기계적 음성의 위화감보다 캐릭터를 마주한다는 감각이 먼저 와야 한다
IO 본부에서 진행하고 있는 TTS 연구 방향은, 일반적인 음성 발화 기술과는 조금 다르다고 할 수 있습니다. AI 앵커가 뉴스를 읽어주는 수준이라면 정보 전달만 잘 되면 되겠지만, 이 연구는 캐릭터성도 연상되면서 감정도 적절히 전해져야만 했으니까요.
<블루 아카이브> 안에는 이미 선생님의 이름을 음성으로 말해주는 기술이 적용되어 있기도 하죠. 이번 TTS 연구는 그것보다도 한 걸음 더 나아간 지점을 바라보고 있습니다.
그때도 지금도 일관된 목표는, 발음이나 음질이 신경쓰이지 않는 수준을 넘어 캐릭터가 나에게 말을 건다는 감각을 주는 것이라고 합니다.

이러한 구현을 위해 TTS 모델을 선정하고, 데이터를 학습시키며 파인튜닝하는 과정을 거칠 필요가 있었습니다.
이미 시중에 TTS 모델은 꽤 있는 편입니다. 하지만 크게 세 가지 선정 기준이 중요하게 적용됐다고 합니다.
캐릭터성이 깨지지 않으면서, 상황에 맞는 감정을 담고, 자연스럽게 말하는 것이 바로 그 기준이었죠.
구체적으로 캐릭터성은 '음색, 발성 습관, 말투와 리듬, 캐릭터에 맞는 성격'까지를 포함하고, 상황에 맞는 감정은 '평상시, 기쁘고 슬프고 화난 상황' 등을 포함합니다. 그러나 '자연스럽다'는 것을 정의하기가 참 어려웠죠.

일본어로 미소녀 스타일의 TTS를 여러 모델을 활용해 만들어보면서 가장 많이 나온 피드백은 크게 4가지였다고 합니다.
단어 사이에 적절한 쉼(끊어읽기 등)을 넣어달라거나, 단어 의미가 달라지지 않게 일본어 장음을 살려달라는 것, 또한 마찬가지로 음 높낮이(인토네이션, 성조)를 적절히 해야 의미 전달에 문제가 없다는 점, 그리고 노이즈를 줄였으면 한다는 점이었죠.

여러 시행 착오 끝에 일본어에 특화된 Style-Bert-VITS2(이하 스타일 버트 비츠2) TTS 오픈소스 학습모델을 선정해 R&D를 진행했다고 합니다.
스타일 버트 비츠2는 문장 기호까지 음소로 취급해 학습하는데, 쉽게 말해 물음표, 느낌표, 마침표, 쉼표 등을 구분해 문장의 의도를 표현해줄 수 있습니다.
또한 같은 캐릭터에게도 다른 스타일을 요구할 수도 있죠. 차분한 캐릭터에게 긴박함을, 특정 이벤트에서는 기쁘게 하는 것 등이 가능합니다.
다만, 한 가지 아쉬움이 있다면 스타일 버트 비츠2는 한국어 TTS를 지원하는 모델이 아니라는 것입니다. 이번 연구의 흐름은 이 모델로도 한국어 미소녀 음성을 만드는 과정까지를 보여줍니다.


먼저 일본어 연구부터 진행했습니다. 강연 현장에선 <블루 아카이브> 일본어 성우들의 데이터셋을 기반으로, 아로나와 프라나의 음성 또는 스타일을 적용한 파인튜닝 결과를 들어볼 수 있었습니다.
음성 데이터셋은 인게임 음성이 아닌, 녹음 스튜디오에서 외부 배경음이 들리지 않는 환경을 만들어, 캐릭터 특유의 말투를 반영한 채로 따로 녹음한 음성을 적용했다고 합니다.
실제 이 모델로 적용한 음성을 들어보면, 쉼표나 느낌표로 표시된 문장을 다르게 말하려 하는 것이 들리고, 일본어 음 높낮이도 이전보다 더 명확하게 나오는 차이를 보여줬습니다.
재밌는 점은 아로나에게 평소의 아로나 스타일로 활기차게 말하게 한 버전, 아로나에게 프라나처럼 상대적으로 무덤덤하게 말하게 한 버전 등이 명확히 구분된다는 것이었죠. 아로나 수치(?)를 더 높이면 더 활기찬 음성을 출력해주기도 했습니다.
 ▲ 넥슨게임즈 김명지 파트장
▲ 넥슨게임즈 김명지 파트장
# 이제 한국어로 이식 개발! 그런데 말처럼 쉽지만은 않다
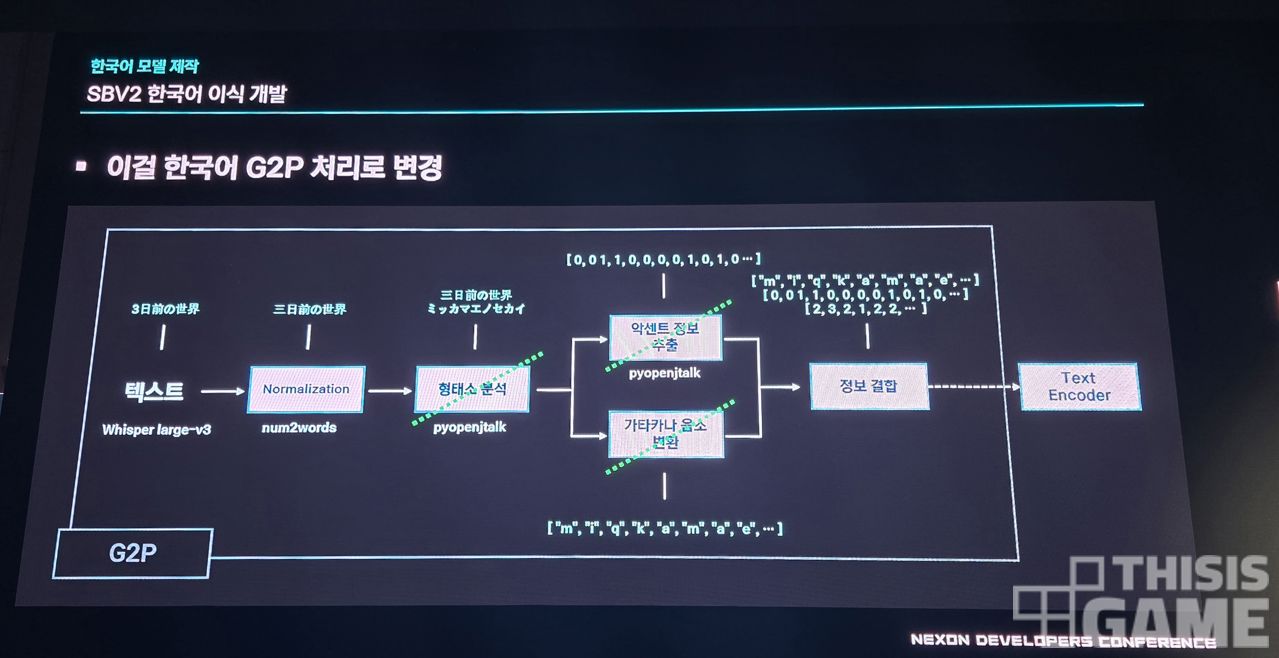
한국어 버전으로 만드는 과정을 소개하려면 스타일 버트 비츠2의 구조에 대한 설명을 짧게라도 하고 넘어가야 합니다. 텍스트가 음성으로 출력되기까지 여러 과정을 거치지만 그 중에서도 G2P와 Bert 모델 부분을 주목해야 하는데요.
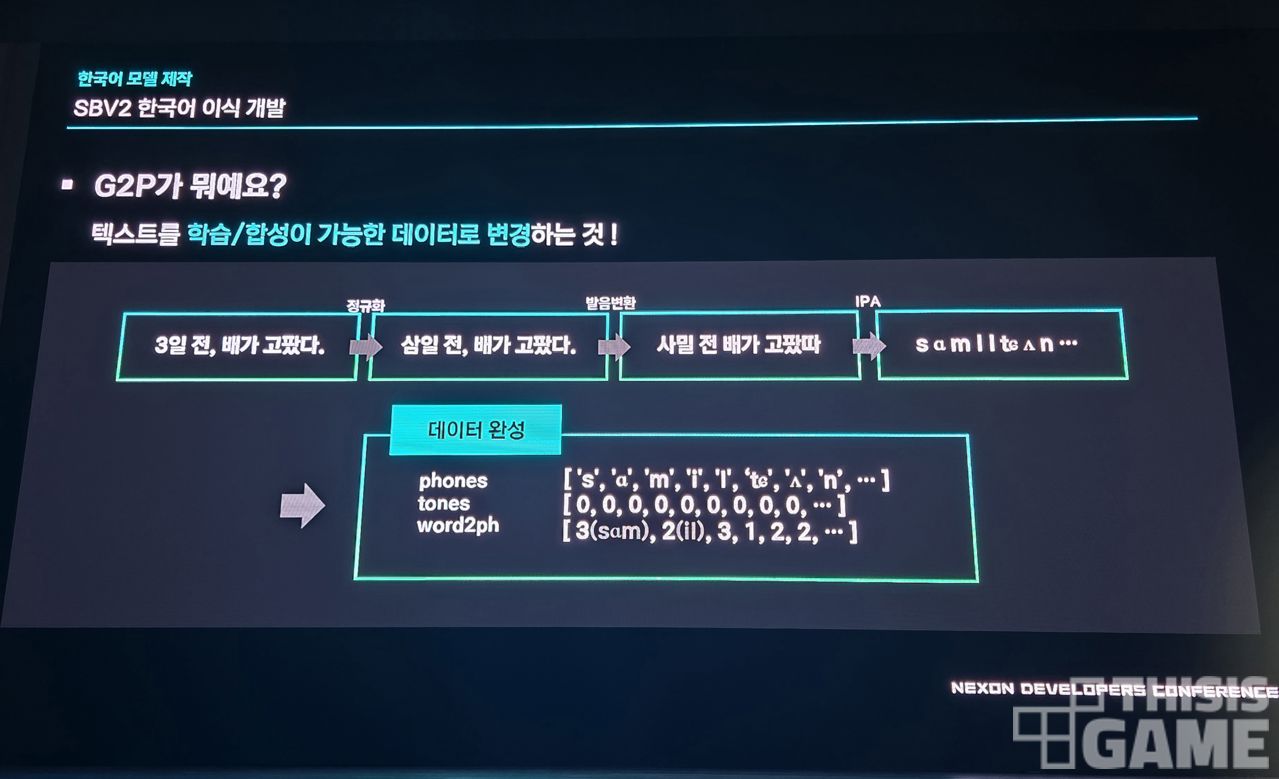
아주 쉽게 설명하면, G2P는 원본 텍스트 문장을 학습 및 합성이 가능한 데이터로 변경하는 것을 말합니다.
"3일 전, 배가 고팠다."에서 숫자를 파악해 "삼일 전, 배가 고팠다."로 바꾸고, 음성화를 위한 발음을 적용해 "사밀 전 배가 고팠따"로 바꾼 뒤, 발음기호 등의 데이터 기호로 바꾸는 작업까지를 말하죠.
일본어의 경우 한자를 뜻에 맞는 발음으로 읽어내는 형태소 분석 과정이 필요하고, 음 높낮이에 따라 발음이 달라지는 악센트 정보도 추출해야 하고, 히라가나 가타카타 음소 변환도 해야 하지만, 이 세 가지 과정은 한국어 모델에선 제외해 적용했다고 합니다.

Bert 모델은 의미를 숫자 벡터로 표현해주는 일을 합니다. 쉽게 말해 똑같은 '일'이라는 단어가 있을 때, 맥락에 따라 숫자 1인지, 날짜 또는 요일의 일인지, 일하는(work) 일인지 구분해주는 역할을 하죠.
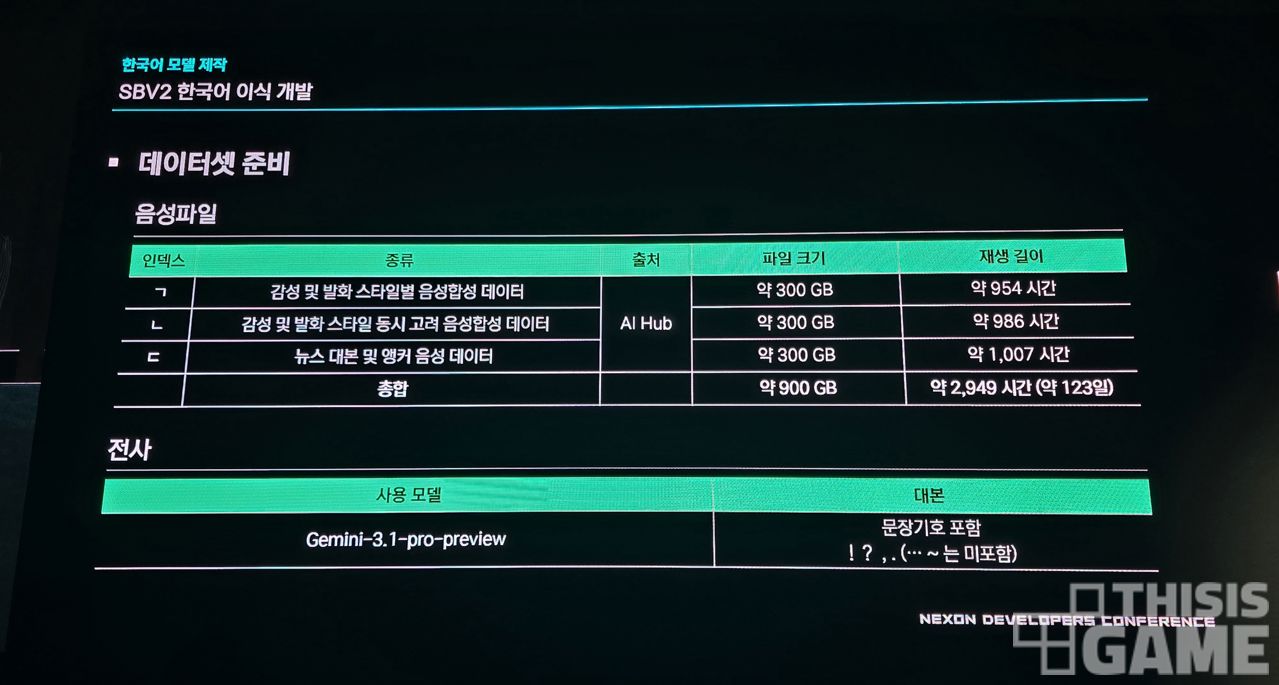
이 과정에서 기반 데이터셋도 여러 버전을 적용해봤고, 제미나이 3.1 프로 프리뷰 모델 등을 사용해 대본 전사 작업 등도 진행해 기반 모델 연구 개발을 했다고 합니다.
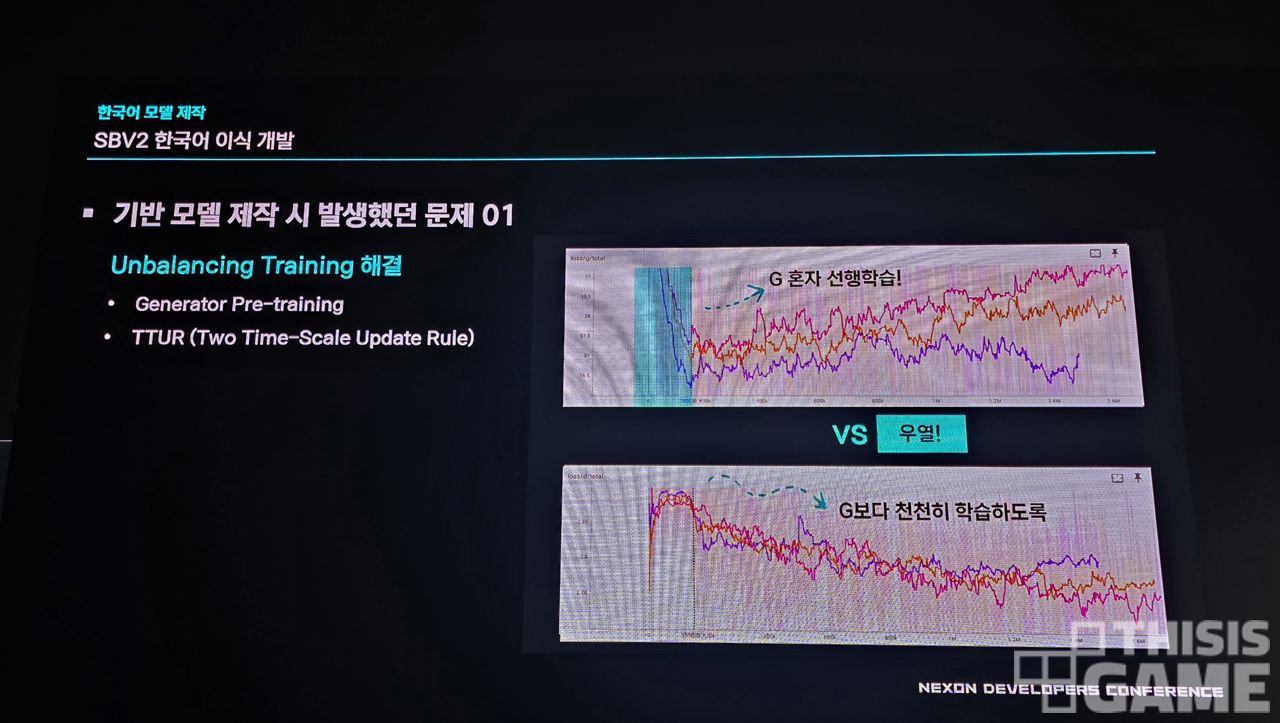
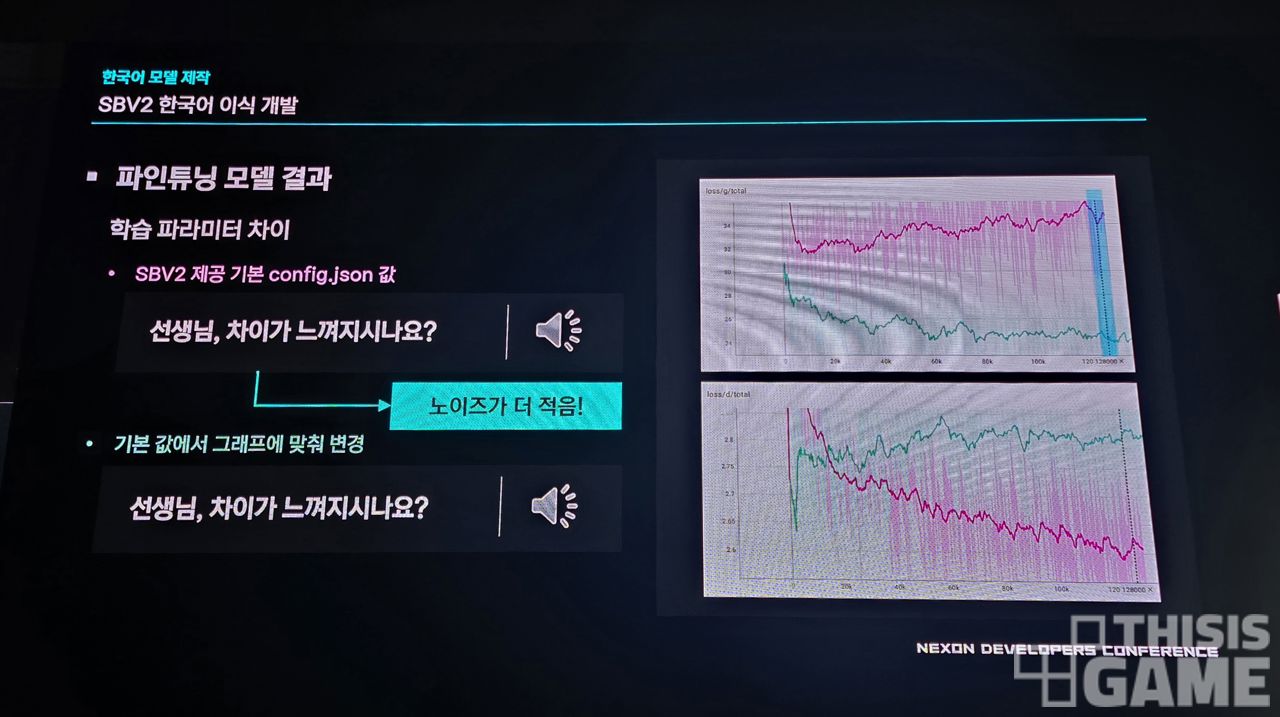
그런데 몇 가지 문제가 발생했죠. G(음성을 생성하는 쪽)와 D(음성을 판별하는 쪽)가 이상적인 상황에서는 균형을 맞추며 완만히 수렴해야 하는데, 판별하는 쪽은 정답지를 가지고 있고, 생성하는 쪽은 이제 기반을 쌓아가는 상황이라 격차가 계속 발생했던 겁니다.
이를 위해 생성하는 쪽에 선행학습을 시키고, 학습 속도 등을 조정하면서 그 격차를 줄였다고 합니다.
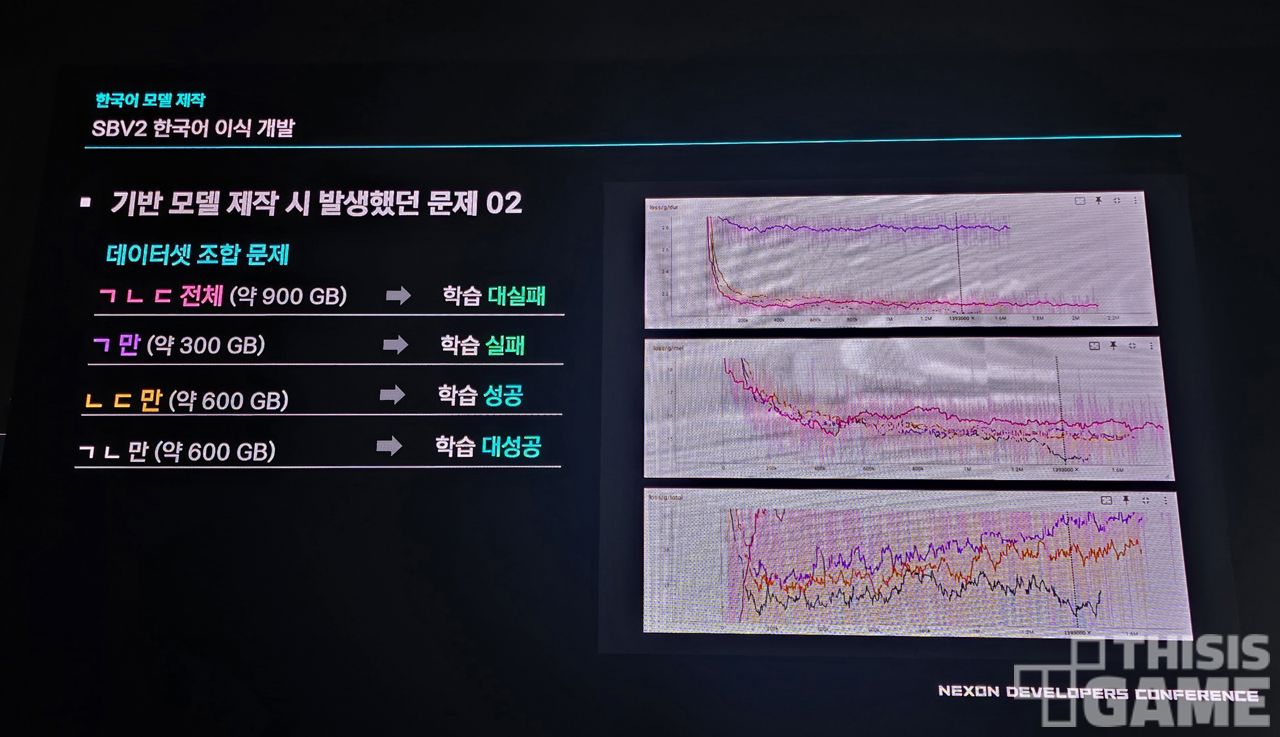
또한 크게 3가지 소스의 데이터셋 중에 세 번째 데이터셋이 포함됐을 때는 로봇 같은 음성이 출력되는 문제도 있었습니다.
정확한 이유를 파악하긴 어려웠지만, 세 번째 데이터셋에 노이즈가 상대적으로 많이 포함되어 있었고, 음성 길이가 달랐던 것이 원인이 아닐까 추측했다고 합니다.
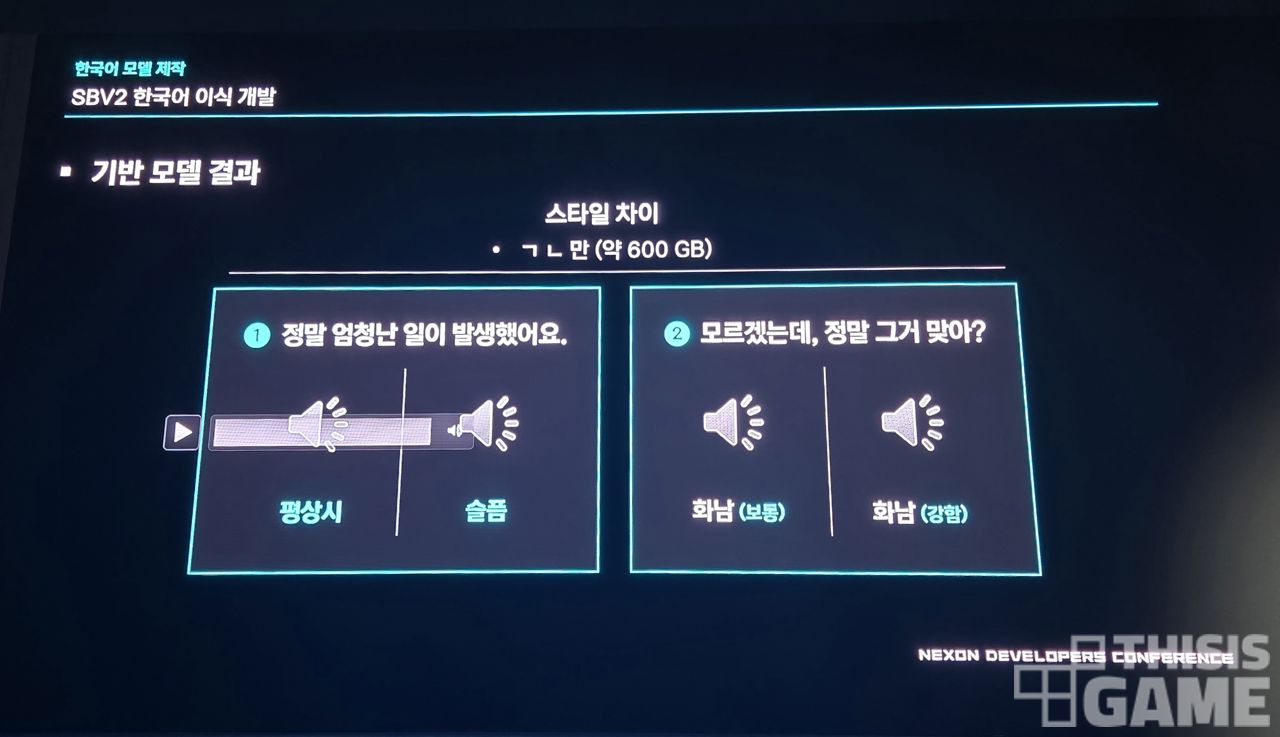
이런 학습 모델의 결과물을 한국어 성우들의 아로나, 프라나 스타일로 파인튜닝을 했고, 그 결과는 각 캐릭터의 스타일로 어느 정도 반영되는 음성 출력물이 나왔습니다.
하지만 이를 고도화하기 위한 과정이 아직 더 필요했죠.
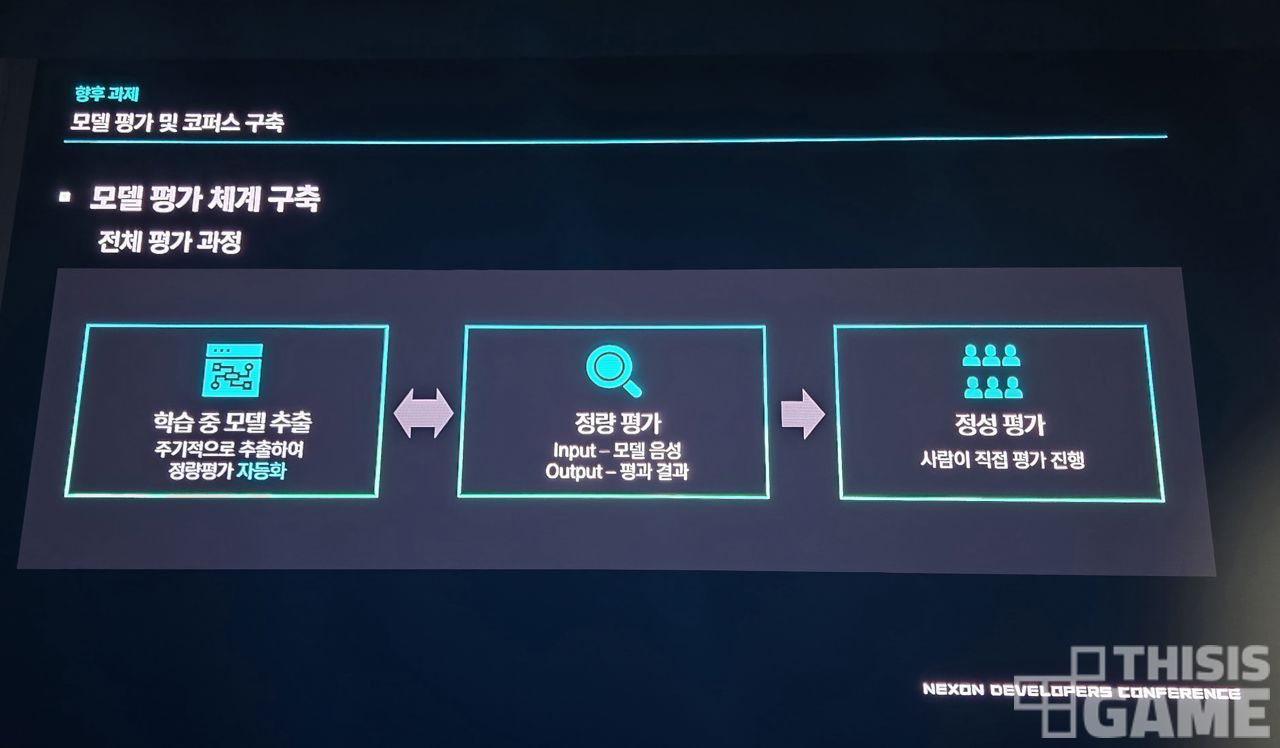
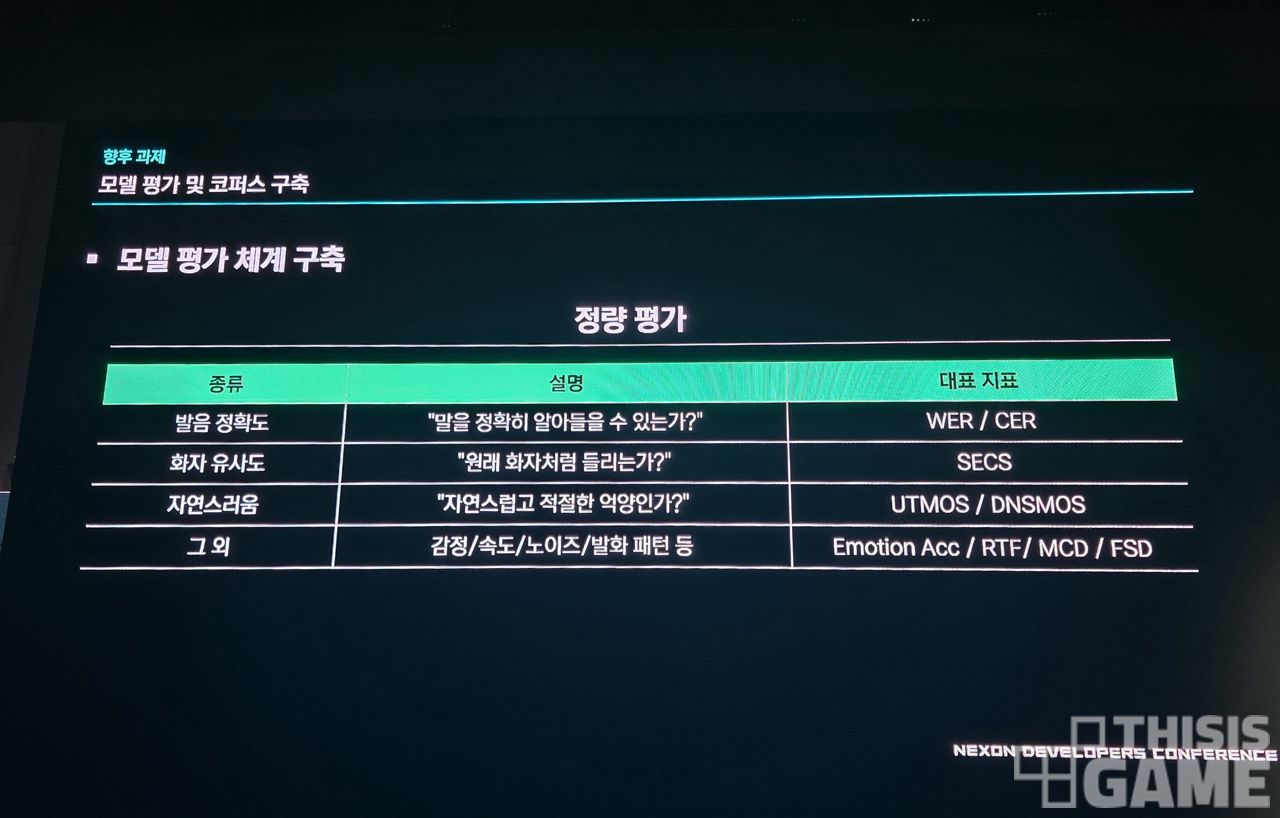
이를 위해, 정량적(그래프 수치를 보고 판단할 수 있는) 평가 과정과 정성적 평가(사람이 직접 듣고 판단하는)를 구분해, 정량 평가 기준을 먼저 통과하는 결과물에 대해 정성 평가를 거치는 식으로 고도화를 하고 있다고 합니다.
일본어 기반 모델의 데이터셋에는 말 늘림표(-), 줄임표(...)가 있었던 것으로 보이는데, 한국어 기반 모델에서는 학습 데이터셋에서부터 이 문장 부호 표현이 포함되어 있지 않았기 때문에, 출력값에서도 이 표현들이 되지 않았던 점이 아쉬움으로 남았습니다.
또한 한국어 발음의 '보스'나 일본어 발음의 '닷슈츠'(탈출) 등이 명확히 출력되지 않는 현상도 나타났습니다. 공통적으로 치찰음이 포함된 단어들이었죠.


결과적으로, 지금까지의 R&D 결과로는 캐릭터의 특징이 담긴 음성을 의미에 맞게 전달하는 것까지는 어느 정도 가능했지만, 디테일한 감정과 뉘앙스의 표현이나, 상황에 맞는 말의 분위기 표현 등은 더 연구하고 개선해야 할 지점들로 남았습니다.
또한 기술적인 연구 및 개선을 거쳐도 넘어야 할 벽들이 더 있는 편이기도 합니다. 특정 캐릭터 보이스를 활용한다고 했을 때 해당 성우가 데이터셋 녹음 및 활용 범위에 동의해야 하고, 게임 및 캐릭터 팬덤 또한 이렇게 기술적 확장을 통해 나온 결과물을 납득할 수 있어야 하기 때문이죠.
강연 전후에 들은 이야기들을 종합해보면, IO 본부에서의 TTS R&D는 기존의 고정된 성우 녹음만으로 채울 수 없는 영역에 대해, 게임 세계 안에서의 몰입감을 크게 높여주거나, 경험을 크게 확장해주는 방향을 지향하며, 기술 개발이 진행되고 있는 듯합니다.
선생님의 이름을 불러주는 것 이상의 또 어떤 참신한 접근법이 나올 것인지 궁금해지는 대목이네요.
 ▲ 넥슨게임즈 김명지 파트장
▲ 넥슨게임즈 김명지 파트장
