[자료제공: 엔비디아]
- 엔비디아 RTX PC·DGX 스파크, <헤르메스> 로컬 AI 에이전트 구동 환경에 최적화
- 알리바바 큐웬 3.6 기반 데이터센터급 에이전틱 AI 성능 구현
- 엔비디아 DGX 스파크, 1,200억 파라미터급 MoE 모델 상시 구동 지원
AI 컴퓨팅 기술 분야의 선두주자인 엔비디아가 엔비디아 RTX PC와 DGX 스파크에서 누스 리서치의 AI 에이전트 <헤르메스>를 로컬 환경에서 지원한다고 밝혔다.
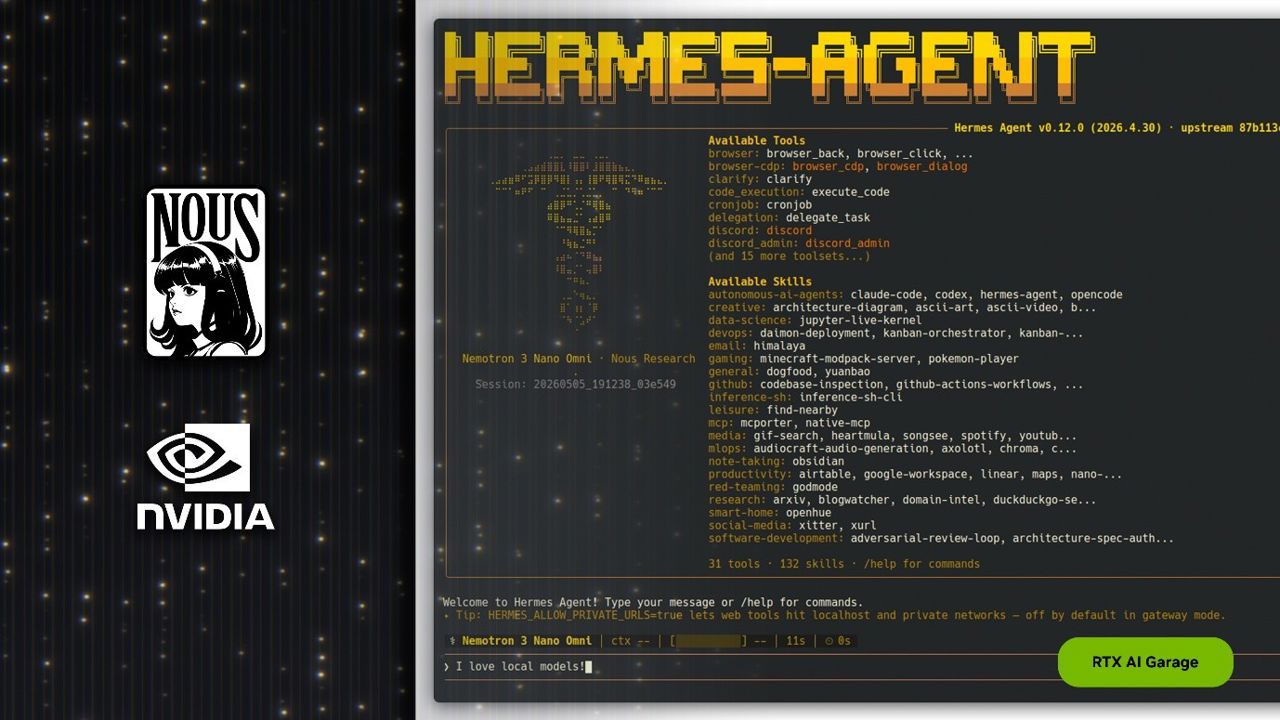
에이전틱 AI는 사용자의 업무 수행 방식을 변화시키고 있다. <오픈클로>의 성공 이후, 커뮤니티는 새로운 오픈소스 에이전틱 프레임워크를 적극적으로 수용하고 있다. 최근 공개된 <헤르메스 에이전트>는 출시 3개월도 채 되지 않아 깃허브 스타 14만 개를 돌파했으며, 오픈라우터에 따르면 지난주 기준 전 세계에서 가장 많이 사용되는 에이전트로 기록됐다.
누스 리서치가 개발한 <헤르메스>는 신뢰성과 자체 개선 기능을 중점으로 설계됐으며, 이는 기존 에이전트에서 구현하기 어려웠던 특성으로 꼽힌다. <헤르메스>는 특정 공급업체나 모델에 종속되지 않는 설계를 기반으로 상시 가동되는 로컬 환경에서의 사용에 최적화돼 있다. 엔비디아 RTX PC, 엔비디아 RTX PRO 워크스테이션, 엔비디아 DGX 스파크는 <헤르메스>를 24시간 최대 성능으로 구동하기에 이상적인 하드웨어다.
알리바바의 새로운 고성능 오픈 웨이트 거대 언어 모델 시리즈인 큐웬 3.6은 <헤르메스>와 같은 로컬 에이전트 구동에 최적화돼 있다. 큐웬 3.6의 27B와 35B 파라미터 모델은 이전 세대의 120B, 400B 파라미터 모델보다 뛰어난 성능을 제공하며, 엔비디아 RTX와 DGX 스파크에서 가속화된 에이전틱 AI 구현을 지원한다.
<헤르메스>, 가속화된 로컬 AI 에이전트 기능
<헤르메스>는 다른 인기 있는 에이전트와 마찬가지로 메시징 앱과 연동되고, 로컬 파일과 애플리케이션에 접근할 수 있으며, 24시간 상시 실행된다. 특히 다음 네 가지 차별화된 기능이 핵심 경쟁력으로 꼽힌다.
-
자체 진화 기술: <헤르메스>는 자체적으로 새로운 기술을 생성하고 개선한다. 복잡한 작업을 수행하거나 피드백을 받을 때마다, 이를 기술 형태로 저장해 시간이 지날수록 스스로 적응하고 성능을 향상시킨다.
-
독립형 서브 에이전트: <헤르메스>는 서브 에이전트를 특정 하위 작업만 수행하는 단기 독립 작업자로 운영한다. 각 서브 에이전트에는 집중된 컨텍스트와 도구 세트가 제공돼 체계적인 작업 구조를 유지하고 혼란을 최소화한다. 이를 통해 더 작은 컨텍스트 윈도우로 <헤르메스>를 실행할 수 있어 로컬 모델 환경에 적합하다.
-
설계 단계부터 고려된 안정성: 누스 리서치는 <헤르메스>에 포함된 모든 기술, 도구, 플러그인을 검증하고 스트레스 테스트를 실시한다. 그 결과 <헤르메스>는 지속적인 디버깅이 발생하는 대부분의 다른 에이전트 프레임워크와 다르게 300억 파라미터급 로컬 모델 환경에서도 안정적으로 작동한다.
-
동일 모델 기준 더 뛰어난 성능: 여러 프레임워크에서 동일한 모델을 사용한 개발자 비교 테스트 결과, <헤르메스>에서 일관적으로 더 우수한 성능을 보이는 것으로 나타났다. 이러한 차별점은 프레임워크에 있다. <헤르메스>는 단순한 얇은 '래퍼'가 아닌 능동형 오케스트레이션 계층으로, 작업 단위의 실행 대신 지속적인 온디바이스 에이전트 작동을 구현한다.
<헤르메스 에이전트>와 이를 구동하는 LLM은 모두 로컬에서 실행되도록 설계됐으며, 이에 따라 하드웨어 성능이 사용자 경험의 품질에 직접적인 영향을 미친다. 엔비디아 RTX GPU는 이러한 워크로드에 최적화되도록 설계됐다.
큐웬 3.6, 로컬 환경에서 구현하는 데이터센터급 인텔리전스
최신 큐웬 3.6 모델은 호평을 받은 큐웬 3.5 시리즈를 기반으로 개발됐으며, 로컬 AI 에이전트의 성능을 한 단계 더 끌어올렸다. 새롭게 공개된 큐웬 3.6 35B 모델은 약 20GB의 메모리만으로도 70GB 이상의 메모리가 필요한 1,200억 파라미터 모델을 뛰어넘는 성능을 제공한다.
또한 큐웬 3.6 27B는 더 많은 활성 파라미터를 갖춘 새로운 고밀도 모델로, 큐웬 3.5 397B와 같은 4,000억 파라미터 모델급의 정확도를 제공하면서도 크기는 16분의 1 수준에 불과하다. 고성능 RTX GPU는 모델의 신속한 성능을 구현하는 데 필요한 컴퓨팅 성능을 제공한다.
이러한 모델은 <헤르메스>와 같은 로컬 에이전트에 최적화돼 있으며, 엔비디아 GPU와 DGX 스파크는 이를 가장 빠르게 실행할 수 있는 환경을 제공한다. 엔비디아 텐서 코어는 AI 추론 성능을 가속화해 더 높은 처리량과 낮은 지연 시간을 구현한다. 이를 통해 <헤르메스>는 다단계 작업을 수행하거나 자체 기술 개선을 단 몇 초 만에 완료할 수 있다.
DGX 스파크, 상시 실행되는 에이전틱 컴퓨터
<헤르메스>와 같은 에이전트는 요청 응답, 다단계 작업 계획, 자율 실행, 자체 개선 등을 지속적으로 수행하도록 설계됐다. 엔비디아 DGX 스파크는 하루 종일 지속되는 에이전틱 워크플로우를 위해 설계된 콤팩트하고 효율적인 독립형 시스템으로, 이러한 에이전트에 이상적인 솔루션이다.
엔비디아 DGX 스파크는 128GB 통합 메모리와 1페타플롭급 AI 성능을 갖춰 1,200억 파라미터 규모의 전문가형 혼합 모델을 상시 실행할 수 있다. 또한 새로운 큐웬 3.6 35B 모델은 더 작은 공간에서 동등한 수준의 인텔리전스를 제공하며, 더 빠른 실행 속도와 함께 사용자가 동시 워크로드를 처리할 수 있도록 지원한다.
사용자는 최적의 성능과 사용 편의성을 위해 <헤르메스 DGX 스파크 플레이북>을 참고할 수 있다. 또한 엔비디아 '빌드 잇 유어셀프' 에이전틱 AI 시리즈에서 진행되는 실습 세션에 등록해 <네모클로>와 <오픈쉘> 기반 자율형 AI 에이전트 구축 방법을 확인할 수 있다.
엔비디아 DGX 스파크는 엔비디아 제조 파트너사를 통해 구입할 수 있다.
엔비디아 하드웨어에서 <헤르메스> 시작하기
엔비디아 하드웨어에서 <헤르메스>를 로컬로 실행하는 방법은 매우 간단하다.
시작하려면 <헤르메스> 깃허브 저장소에 접속한 뒤, 원하는 로컬 모델, 런타임과 연동할 수 있다. <라마.cpp>, <LM 스튜디오>, <올라마>를 통해 큐웬 3.6과 함께 <헤르메스>를 실행할 수 있다. <헤르메스 에이전트>는 <LM 스튜디오>와 <올라마>를 기본으로 지원해 로컬 에이전트를 가장 손쉽게 구축할 수 있는 환경을 제공한다.
개인용 에이전트의 가능성을 탐색하는 로컬 AI 애호가부터, 워크플로우를 위한 로컬 툴링을 개발하는 개발자까지, 엔비디아 하드웨어 기반 <헤르메스>는 독보적인 성능과 신뢰성을 갖춘 기반을 제공한다.
최신 오픈 모델과 엔비디아 RTX 하드웨어에 최적화된 에이전트 관련 업데이트는 RTX AI 개러지를 통해 지속적으로 공개될 예정이다.
RTX AI PC 최신 업데이트 사항
-
엔비디아 RTX PRO GPU는 <라마.cpp>에서 큐웬 3.6 모델 실행 시 최대 3배 빠른 토큰 생성 속도를 제공한다. 이를 통해 로컬 AI에 필요한 실시간 응답성을 구현하며, 에이전트가 다단계 작업을 처리하고 자체 스킬을 개선해 끊김 없는 워크플로우를 유지할 수 있도록 지원한다.
-
구글의 <젬마 4> 26B 및 31B 모델이 이제 NVFP4 체크포인트로 제공돼 엔비디아 블랙웰 GPU에서 더 빠른 성능을 발휘한다. NVFP4 체크포인트를 구글의 새로운 멀티 토큰 프리딕션 드래프터와 결합해 동일한 출력 품질에서 최대 3배 더 빠른 추론 속도를 제공한다. 이를 통해 엔비디아 GPU에서 최첨단 수준의 추론 작업을 로컬로 실행할 수 있다.
-
4월에 출시된 <미스트랄 미디엄> 버전 3.5에는 <라마.cpp>와 <올라마>의 호환성 업데이트가 포함돼, 사용자가 엔비디아 RTX PRO와 DGX 스파크 시스템에서 실행할 수 있다.
-
엔비디아는 최근 보안성을 강화하고 로컬 모델을 지원함으로써 엔비디아 장치에서 <오픈클로> 환경을 최적화하는 오픈소스 스택인 엔비디아 <네모클로>를 공개했다. <네모클로>는 WSL2를 지원해 마이크로소프트 플랫폼의 애호가와 개발자들에게도 혜택을 제공한다.